บทความนี้เป็นการสรุปเนื้อหาจากที่เรียนนะครับ ปนความคิดเห็นผู้เขียนไปด้วย อาจจะมึน ๆ บ้าง การสเกลคืออะไร เตรียมการสเกลไว้ดีมั้ย ทำไมต้องทำด้วย ไม่ทำได้มั้ย
คำตอบทั้งหมดคงจะตอบว่า ได้ครับ แน่นอนว่าทุกอย่างถ้าเราอยู่ในทรัพยากรที่จำกัดมาก ๆ บางทีการวางโครงสร้างของเราอาจจะไม่ต้องทำให้มันรองรับการ Scale Up ก็ได้ แต่ถ้าเราสามารถที่จะเขียนได้หละ สามารถเขียนเปิดทางแอพพลิเคชั่นให้มันเปิดทางการสเกล หรือ การขยายได้หละ มันจะดีกว่ามั้ย
ทำไมเราต้องเปิดทางให้ Application สามารถ Scale ต่อไปได้
การเวลาเปลี่ยน ทุก ๆ อย่างที่อาจจะคิดว่าดีที่สุดในช่วงเวลานั้นอาจจะไม่ได้ดีที่สุดเสมอไป แล้วถ้าเราคุมได้หละ ว่าผู้ใช้เราเท่านี้ ยังไงยังไง ก็เท่านี้ เรายังต้องสเกลอีกมั้ย ก็ต้องบอกว่าตราบใดที่มันมีการใช้งานมันจะมีอะไรบางอย่างที่เพิ่มขึ้น อยู่เสมอ ๆ เช่น เราทำแอพพลิเคชั่นสำหรับแม่ค้า 5 เคาท์เตอร์ เป็นระบบ POS ยังไง เราก็จะไม่เพิ่มเคาท์เตอร์ แต่ Data หละ Log ข้อมูลหละ มันเพิ่มขึ้นทุก ๆ วันที่ลูกค้ามาใช้งาน ความต้องการในการใช้บริการ Storage ก็จะเยอะมากขึ้น จริงมั้ย เพื่อให้ง่ายขึ้นเราจะมาวิเคราะห์ปัจจัยต่าง ๆ ที่มันจะบอกว่าทำไมเราควรเตรียมการให้แอพพลิเคชั่นของเราสเกลได้
1. ปัจจัยภายนอกที่มีผลต่อการ Scale
ปัจจัยโดยตรงของการ Scaling
-
อย่างที่กล่าวไว้แล้วว่า ระบบต่อให้เราจะมีคนใช้จำนวนจำกัดแล้ว แต่เวลาหนึ่ง ถ้าระบบถูกใช้ไปเรื่อย ๆ Process จะถูก Fork ออกมาขึ้นเรื่อย ๆ Data, Event ต่าง ๆ จะถูกปล่อยออกมาเรื่อย ๆ วันหนึ่งเราจะทำยังไง เมื่อ Storage ของเราเต็มเกินที่จะรับข้อมูลเหล่านี้ การเพิ่มพื้นที่ Storage ก็ถือเป็นการเพิ่ม Vertical Scaling อย่างหนึ่งแล้ว
-
แม้จะมอง หรือ ไม่มองถึงการเพิ่มขึ้นของผู้ใช้ แต่การที่โปรแกรมหนึ่งตัว อาจจะต้องมีการทำงานร่วมกันกับโปรแกรมอีก 1 ตัว มันก็ย่อมทำให้ระบบต้อง Concurrence มากขึ้น เช่น แต่ก่อนห้างสรรพสินค้าอาจจะมีการรับชำระเงินสดเพียงอย่างเดียว ต่อมารับบัตรเครดิต รับเดบิต หรือ รับ Prompt Pay มันทำให้การเพิ่มงานของระบบมันเพิ่มขึ้น แน่นอนว่าถ้าเรามีทรัพยากรต่าง ๆ เท่าเดิม สิ่งเหล่านี้ ย่อมรับภาระงานที่หนักขึ้น
ปัจจัยโดยอ้อม ที่ทำให้เราควรจะ Scaling
-
บางทีการทำงานด้วยระบบของเราในเวลาหนึ่ง ความเร็วขนาดนี้จะเป็นเรื่องที่ปกติ ยอมรับได้ แต่เมื่อโลกมันผ่านไป การทำงานด้วย Speed แค่นี้อาจจะช้าเกินไปสำหรับระบบของเรา
-
เมื่อสักครู่ เรายังไม่มองถึงการเพิ่มขึ้นของผู้ใช้ แล้วถ้ามีการเพิ่มขึ้นของผู้ใช้หละ แน่นอนว่า Service ที่เราวางเอาไว้ อาจจะไม่เพียงพอต่อการเพิ่มขึ้นของผู้ใช้ระดับหนึ่ง และอาจจะเกิดการทำงานที่มากเกินไป และเกิดการ Overloading ได้
-
บางทีการทำงาน Memory เอย Data เอย มันไม่มีพื้นที่พอแล้ว แล้วมันจำเป็นจริง ๆ ที่อาจจะต้องไปรบกวน Service ตัวอื่น ๆ แล้วประสิทธิภาพของ Service ตัวอื่น ๆ ก็จะน้อยลง หรือ พังไปเลยก็ได้
-
บางทีเราอยากจะเพิ่ม Processing Power แต่เออ Hardware ผม มันไม่รองรับแล้วหละครับ
โอเค เราได้กล่าวถึงปัจจัยที่เราไม่ได้ต้องการจะให้มันเกิด หรือ ไม่รู้ด้วยซ้ำว่ามันจะเกิดขึ้น ทีนี้เราจะมาพูดถึงปัจจัยภายใน หรือ คือเรารู้ตั้งแต่แรกแล้วว่าเราต้องการสิ่งนี้ เราต้องการให้มันตอนสนองสิ่งเหล่านี้ แน่นอนว่ามันอาจจะมี Extra Work บ้าง แต่มันก็ทำประโยชน์ให้เรา เราเลยเตรียมการสเกลเอาไว้
2. ปัจจัยภายในที่มีผลต่อการ Scale
2.1 ความต้องการความพร้อมใช้งานสูงสุด (High Availability)
คือ Service หรือ Application ของเรานั้นเราต้องการให้มันสามารถทำงานได้ ตอบสนอง Request ของผู้ใช้ได้ตลอดเวลา หรือ สูงสุดตามที่เราสามารถทำได้ หรือเราอาจจะมีสัญญา Service Level Agreement (SLA) กับลูกค้าของเราไว้ โดยส่วนใหญ่ในเรื่องของความพร้อมใช้งาน เราจะวัดกันเป็นจำนวนของตัวเลข 9 เช่น Uptime 99% เราจะเรียก Two nines หรือ Uptime 99.999% เราจะเรียน Five nines ระบบไหนถึง Five nines ถือว่าที่สุดแล้วว
โดยคำจำกัดความของ High Availability หรือ HA นั้น หมายถึง ระบบสามารถทำได้ตลอด ตามข้อตกลงที่วางไว้ โดยไม่ได้บอกว่าระบบจำเป็นต้องตอบสนองทุกอย่างถูกต้องนะ ถ้าพบว่ามี Request ระบบหาเส้นทางไม่เจอ ตอบสนองไม่ได้ แล้วตอบกลับไปว่า 502 Bad Gateway หรือ 503 Gateway Timeout แค่นี้ก็ถือว่าบรรลุวัตถุประสงค์ของ HA แล้ว
แล้วจะทำยังไงให้ได้ HA
การที่จะให้ระบบบรรลุวัตถุประสงค์ของการพร้อมทำงานนั้น สิ่งที่เราควรทำคือ เราต้องเตรียมให้พร้อม เช่นถ้ามีโหนด หรือ Server ตัวหนึ่งล่มไป ระบบก็สามารถใช้อีกตัวหนึ่งแทนได้ การวางรูปแบบ Master-Slave ถือเป็นวิธีหนึ่งที่นิยมกันทำเพื่อบรรลุเป้าหมายของ HA คือมีการเตรียม Server หนึ่งเอาไว้สำหรับการทำงานหลัก และมี Server สักตัวสองตัวเป็น Slave มีการทำ Replication อยู่ เมื่อมีการล่มของ Master ไอตัว Slave ก็สามารถเลือกกัน หรือ โหวตกันขึ้นมาเป็น Master แทนได้ เป็นต้น
การทำ Master-Slave มี 2 แบบในการซิงค์ข้อมูลกัน
จะว่าไปแล้ว วิธีการทำ Master-Slave ก็มีการซิงค์ข้อมูลกันสองวิธีด้วยกัน
- การมี Monitoring Node คือ มีโหนดตัวหนึ่ง เสมือนมาจาก Client จะชี้ไปที่ตัว Master อยู่เสมอ ถ้ามันไม่สามารถติดต่อเชื่อมไปยัง Master Node ได้ มันก็จะไปที่ Slave ทันที แน่นอนข้อเสียของวิธีนี้คือ Node ตัวนี้จะเป็น Single Point of Failure คือ ถ้า Node ตัวนี้พังขึ้นมาระบบของเราจะพังทันที
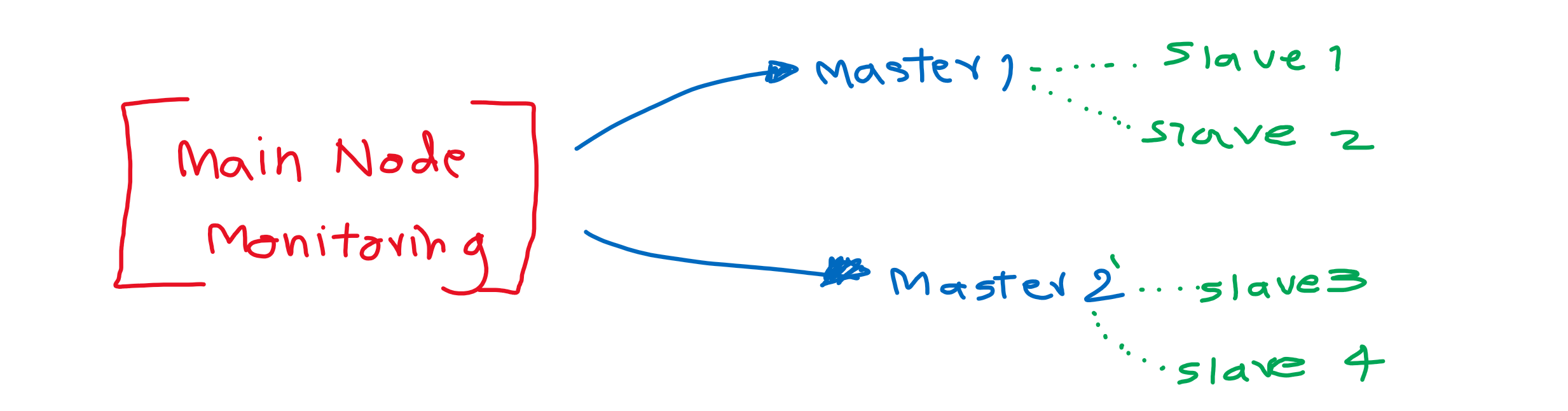
- การไม่มี Monitoring Node แต่ใช้ Heartbeat ในการสื่อสารข้อมูลกัน โอเคว่ามันมีทั้งตัว Master และ ตัว Slave แต่ทุกตัวจะเหมือนเป็น Peer to Peer แล้วคุยกันบอกว่าฉันยังอยู่นะ เทคนิคนี้ใช้ใน MongoDB Replica ครับ แน่นอนว่ามันจะไม่ใช่ Single Point of Failure แต่ว่าถ้าสัญญาณ Heartbeat เกิดความผิดพลาดขึ้นมา โดย Node ไม่ได้เสียหละ จะเกิดอะไรขึ้น จะมีการสร้าง Master ขึ้นมามากกว่า 1 ตัวไหม อันนี้อาจจะเป็นปัญหาได้
 Heartbeat in MongoDB Replica เอารูปมาจาก Doc ของ MongoDB นะครับ
Heartbeat in MongoDB Replica เอารูปมาจาก Doc ของ MongoDB นะครับ
2.2 ความต้องการให้ระบบมีความทนทานต่อการล้มเหลว (Fault Tolerance)
FT หรือ Fault Tolerance คือการทำให้ระบบของเรานั้นล้มเหลวให้น้อยที่สุด ส่วนนี้ล่ม ส่วนอื่นที่ไม่ล่มก็ควรจะต้องใช้งานได้ และจะต้องมีการแก้ไขปัญหาได้เองให้ได้ดีและเร็วที่สุด เท่าที่เราจะทำได้ (เขียน Catch Error เอาไว้เลย) มันจะไม่ใช่แค่การตอบว่า 502 Bad Gateway แล้ว แต่จะต้องเป็นการแก้ปัญหาและ Return สิ่งที่ผู้ใช้ต้องการ หรือ
ถ้าเรามีเว็บเซิฟเวอร์ แล้ว เว็บไซต์รีเควสจากผู้ใช้ A ล่ม ผู้ใช้ B จะรีเควสมา ก็ควรจะยัง Request ได้ ยิ่งถ้าสมมติรีเควสที่มาจาก A กับ B อยู่ใน Internal Port ต่างกัน เช่น A กับ B อาจจะเข้ามาที่พอร์ต 80 (HTTP) ทั้งคู่ รีเควสมายัง Sub URL หนึ่ง ซึ่งเรา Reverse Proxy ไปที่ Port 3000 กับ B เข้ามายัง Sub URL ที่เรา Reverse Proxy ไปที่ Port 4000 แม้ Request ของ A จะมีปัญหา Request ของ B ก็ยิ่งไม่ควรจะมีปัญหา
การแก้ปัญหา Fault Tolerance นั้นเป็นการเพิ่มระบบของเราให้มีความ High Availability ขึ้นส่วนหนึ่งเหมือนกัน
การทำ Redundancy เพื่อแก้ปัญหา Fault Tolerance โดยตรง
เพื่อการให้ระบบของเราล้มเหลวได้น้อยที่สุดนั้น การมีอีกระบบ ๆ หนึ่งที่ Replication จาก Primary Node ไปและทำงานคู่ขนานกันไป ถ้ามีระบบใดระบบหนึ่งพังลงไป ก็สามารถใช้อีกระบบหนึ่งทดแทนได้ทันที มีการนำมาใช้ในระบบที่ต้องการความทนต่อความล้มเหลว อย่างโครงการของสถานีอวกาศ ของรถยนต์ต่าง ๆ ก็มี Node ที่ทำงานพร้อม ๆ กันแบบนี้เช่นกัน อาจจะมีการเพิ่ม Voting System เข้ามาให้พวก Secondary Node โหวตกัน ถ้าหาก Primary ล่มไป ว่าใครที่จะมาทำงานเป็น Primary ต่อไป
จะเห็นได้ว่า MongoDB Replica ก็มีระบบที่มีความสามารถในการทำ Fault Tolerance เหมือนกัน เพราะ มีการทำ Replication อยู่ตลอดเวลา และมี Vote System ที่ใช้ในการเลือกตัวใหม่ ขึ้นมาแทนกรณี Primary Node ได้พังลงไป
Forward Error Correction
คือ การเพิ่มพลังความสามารถของตัวฝั่ง Reciever ให้รับรู้ได้ทันทีว่าขณะนี้เกิด Error ขึ้นนะ และให้ฝั่งผู้รับแก้ของมันเอง เพราะบางอย่าง ต้องแก้ที่ผู้รับเท่านั้น เราอาจจะไม่สามารถแก้ไปจากผู้ส่งได้ ผู้ที่ใช้ก็เช่น พวกเทคโนโลยีเกี่ยวกับโทรศัพท์ เช่น CDMA, GSM เป็นต้น
การทำ Checkpointing
ก็คือมีจุดเช็คพอยต์อยู่เรื่อย ๆ ถ้าหากระบบพังตรงนี้ก็กลับไปทำที่จุดเดิมที่มันเคย Checkpoint เอาไว้ เรียกว่าการอนุญาติให้มันทำการกู้คืนความล้มเหลวจากจุดที่มันทำสำเร็จครั้งล่าสุดไป มีการ Save ข้อมูลที่จำเป็นจากการ Running ของแอพพลิเคชั่นไว้ที่จุด Checkpoint และยังสามารถรีสตาร์ทจุด Checkpoint นี้ ที่เครื่องเดิม หรือ เครื่องอื่น ๆ ก็ได้
การทำ Distributed Checkpointing
เป็นหนึ่งการต่อยอดการทำจาก Checkpointing เนื่องจากระบบต่าง ๆ ที่เราเขียนขึ้นมานั้น มันไม่ได้อยู่บนเวลาตัวเดียวกันทั้งหมด อาจจะอยู่คนละสัญญาณนาฬิกา ดังนั้นการทำ Checkpoint บนระบบแบบกระจาย หรือ Distributed System จึงมีความยุ่งยากกว่าตรงที่เราต้องมีการเซ็ทจุด Concurrent Checkpoint ที่เป็นจุดที่ทุก ๆ Stream หรือ ทุก ๆ งานของเรามีสเตทเดียวกัน
สมมติผมมีรถยนต์ เครื่องบิน มอเตอร์ไซค์ จักรยาน และ คนเดินธรรมดา จุด Checkpoint แรกที่อาจจะมีร่วมกันได้ก็คือ จุด Start ทีนี้ผมก็จะต้องกำหนดจุด Checkpoint ที่สองที่ทุก ๆ อย่างมาเป็นสเตทเดียวกัน เช่นตอนแรกผมบอกว่าอยู่ที่สนามบินสุวรรณภูมิ จุด Checkpoint ต่อไป ก็อาจจะเป็นสนามบินเชียงใหม่ ถ้าผมเก็บ Checkpoint ที่ปั้มน้ำมัน เครื่องบินอาจจะมาไม่ได้
สมมติเรามีรถอย่างเดียว และเราตั้ง Checkpoint ไว้ที่ปั้มน้ำมัน ถ้ารถเสีย ให้กลับมายังปั้มน้ำมันล่าสุดที่มันเคยมา แต่นี่ถ้ารถเสีย รถต้องกลับมาที่สนามบินครั้งล่าสุดที่เคยเจอกัน และทุก ๆ อย่างด้วย พอกลับมาเรื่องของระบบของเราการจัดการ Distributed Checkpointing มันก็จะยากกว่า Checkpointing ปกติประมาณนี้แหละ
เอกสารอ้างอิง Fernando Doglio. Scaling Your Node.js Apps. Appress,2018 - Scaling Your Node.js App in Google Books

> Theethawat Savastham (Tin)
ธีร์ธวัช สวาสดิ์ธรรม (ติน)
จากนักศึกษาบ้าๆ คนนึง ตอนนี้กลายเป็นคนบ้าๆ ที่พัฒนาเว็บไซต์และระบบต่างๆ มากมาย ผู้ก่อตั้งและสมาชิกเพียงคนเดียวของ The Duck Creator และยังเป็นนักศึกษาวิศวกรรมคอมพิวเตอร์ ระดับปริญญาโทอีกด้วย